Introduction to Data Visualization
So far, we have focused on cleaning and merging data, but the primary question has remained: for what purpose? In this lesson, we’ll begin exploring ways to visualize our data, which will aid our understanding. Additionally, time permitting, we’ll delve into more advanced data transformations that will assist in data visualization.
Final Merging of Data
Toggle to See My Solution
In our last lesson, we were left with the task of performing a final merge of our two datasets:
I outlined many of the steps in the assignment description, but let’s go through them one-by-one.
- Importing the Data
Initially, we need to add our data to our spreadsheet. I used the standard import feature, but you can also directly import from another Google Sheets if you prefer.
- Resizing and Inspecting the Data
Upon importing, you should find a new sheet at the bottom, which you can name index-of-dh-abstracts if it isn’t already. You’ll also notice that the text size within each cell is considerably large, complicating data inspection.
To address this, you can select all rows containing data, press shift, and then drag the cursor on the last row to resize them all simultaneously.
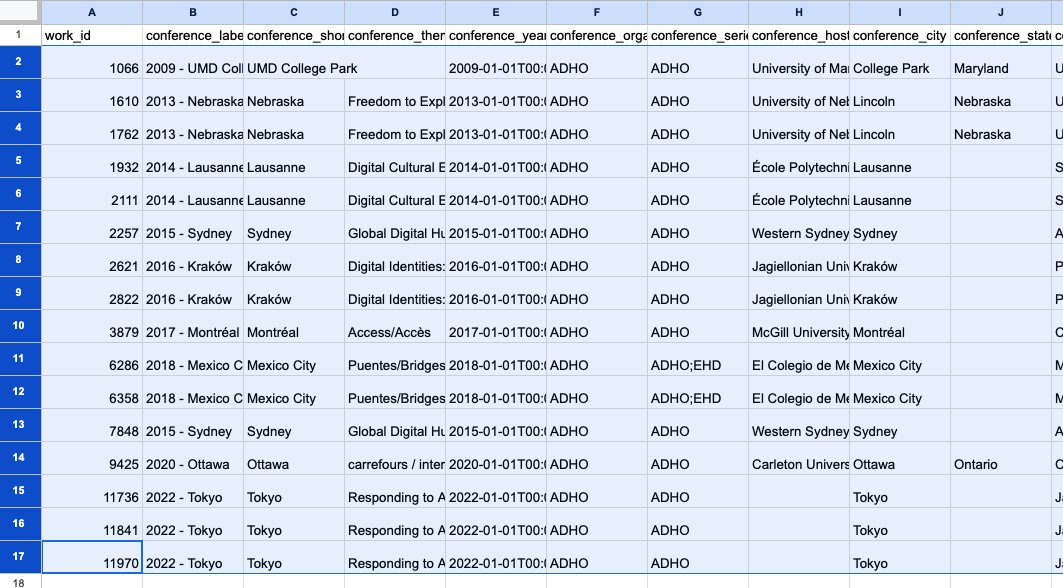
- Identifying Shared Columns
Upon inspecting both our datasets, it’s evident that they have the work_id column in common. This will be our reference column for merging, even if the datasets are of different sizes.
- Merging the Datasets into a New Sheet
The merging process entails several steps:
-
Start by creating a new sheet in your spreadsheet, which can be done by clicking on the
+button situated at the bottom. Name this new sheetFinal Merged Dataset. -
Next, you’ll need to import your
Merged Datasetinto this sheet (though if you prefer, you could importindex-of-dh-abstractsfirst).
We can either do this manually or use the ARRAYFORMULA function:
=ARRAYFORMULA('Merged Dataset'!A1:S18)
Once you’ve imported the data, the remaining task is to integrate the other dataset into the same sheet. This can also be done using a formula, whether designed from scratch or with assistance from ChatGPT.
Here are some previously discussed formulas for merging:
- Merging two datasets with a shared column:
=ARRAYFORMULA(IF(A2:A239="", "", IFERROR(VLOOKUP(A2:A239, {'All DH Tools Revised'!A2:A18, 'All DH Tools Revised'!B2:M18}, COLUMN(B1)+1, FALSE), "")))
- Merging two datasets with a shared column and autofilling the other columns:
=ARRAYFORMULA(
IF(A2:A239="", "",
IFERROR(VLOOKUP(A2:A239, 'All DH Tools Revised'!A2:M18, SEQUENCE(1, 12, 2), FALSE), "")
)
)
So our code might look like the following since we have A1:S18 in Final Merged Dataset and A1:W17 in index-of-dh-abstracts:
=ARRAYFORMULA(
IF(A2:A18="", "",
IFERROR(VLOOKUP(A2:A18, 'index-of-dh-abstracts'!A2:W17, SEQUENCE(1, 23, 2), FALSE), "")
)
)
However, this isn’t entirely accurate since in our Final Merged Dataset, the work_id is in column S. Hence, the formula must be adjusted:
=ARRAYFORMULA(
IF(S2:S="", "",
IFERROR(VLOOKUP(S2:S, 'index-of-dh-abstracts'!A2:W17, SEQUENCE(1, 23), FALSE), "")
)
)
If we input this formula we’ll see that we get the correct values for the rows but are missing the columns.
We can ask ChatGPT for help to fix the issue (toggle for answer):
Prompt:
I have two Google Sheets that I would like to merge. The first is called
Merged Datasetand has a range ofA1:S18and the second is calledindex-of-dh-abstractsand has a range ofA1:W17. Both datasets contain a column calledwork_id, which is in columnSinMerged Datasetand is in columnAinindex-of-dh-abstracts. I want to merge these two into a new sheet calledFinal Merged Datasetand also both these sheets are already in the same Google Sheet as individual sheets. Help me complete this task
ChatGPT Response:
Merging the two Google Sheets based on a common column can be achieved using the VLOOKUP function or the QUERY function in Google Sheets. Here’s a step-by-step guide to merge the two sheets into a new sheet called Final Merged Dataset:
- Create the New Sheet:
- Open your Google Sheet document.
- At the bottom, click on the ‘+’ icon to add a new sheet.
- Rename the new sheet to
Final Merged Dataset.
- Copy the Data from
Merged Dataset:- Go to the
Merged Datasetsheet. - Select the range
A1:S18and copy it. - Go to
Final Merged Datasetand paste the data starting from cellA1.
- Go to the
-
Use VLOOKUP to Fetch Data from
index-of-dh-abstracts:In this step, you’ll retrieve the additional columns from the
index-of-dh-abstractssheet using theVLOOKUPfunction.- In the
Final Merged Datasetsheet, go to cellT1. - This is where you’ll start to pull in data from the
index-of-dh-abstractssheet, excluding thework_idsince it’s already present. - Enter the following formula in
T1:=IFERROR(VLOOKUP($S1, 'index-of-dh-abstracts'!$A$1:$W$17, COLUMN(B1), FALSE), "") - Drag the formula to the right to cover all columns you want to import from
index-of-dh-abstracts(up to columnVsince you’re excluding the first columnwork_id). - Then, drag down the formula to row
18to populate all rows with data from the second sheet.
- In the
-
Refining the Final Dataset:
The steps above will give you the merged data in
Final Merged Dataset. However, if there are any discrepancies or formatting issues, you’ll need to manually adjust them. It’s also a good practice to review the data and ensure that everything was merged correctly.
Remember: Always create a backup of your original data before making significant changes or manipulations. This way, if something goes wrong, you can always refer back to the original data.
We can get the following formula:
=IFERROR(VLOOKUP($S1, 'index-of-dh-abstracts'!$A$1:$W$17, COLUMN(B1), FALSE), "")
This formula differs from our attempt but shows some similarities, such as the use of the IFERROR, VLOOKUP, and COLUMN functions.
And now we should have the following data in our Final Merged Dataset:
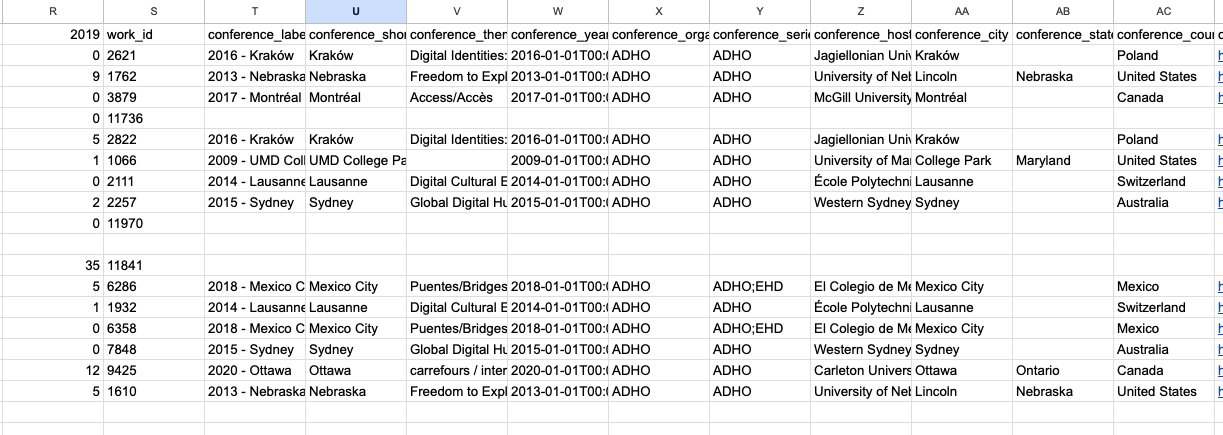
We could keep tweaking this formula to work with our original attempts but this is a good example of how we can use ChatGPT to help us with our formulas.
Also if you are having any issues be sure to check that your data types in your work_id column is identical. Remember computers are powerful, but dumb. You have to often specify things that most humans would understand implicitly.
Data Visualization
Now that we have our final merged dataset, it’s time to consider how we might use this data to address our primary inquiry: how do the popularity of DH tools from this class compare to the DH tools in the Index of DH Abstracts?
Currently, we can utilize three datasets to answer this:
- Our class dataset
- The tools dataset from the blog post titled “What Tools are Popular in DH”
- The tools dataset from the Index of DH Abstracts
When thinking about how to answer this question we need to start thinking about how we would make this comparison. Intuitively, a counting approach stands out, particularly given that some of our columns already provide such counts (tool_count, along with the year-based data from the blog post).
While a cursory glance at these results reveals certain trends, Google Sheets’ built-in visualization capabilities can enhance our understanding of the data.
Visualizing Data in Google Sheets
Google Sheets has a number of built-in functionality to help us visualize our data. We can access this functionality by selecting our columns that contain numeric data, and then clicking on the Insert menu and then selecting Chart (or the icon in the menu bar).
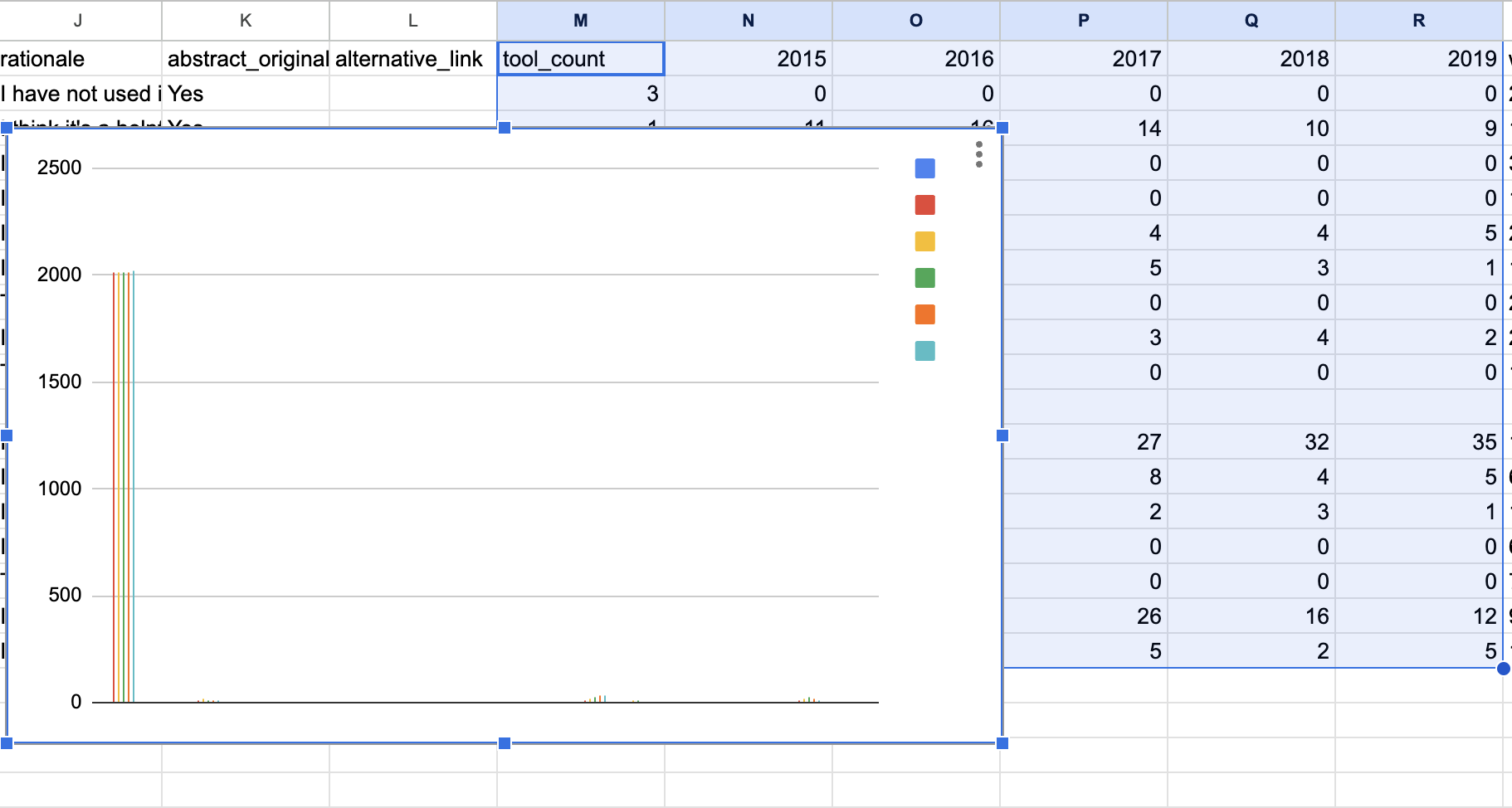
At first glance, the generated chart might seem overwhelming, yet it provides valuable insights into Google Sheets’ data interpretation. For a deeper understanding, utilize the edit chart feature. Clicking the three small circles atop the chart and selecting Edit Chart will open the Chart Editor, granting access to tools for chart type alteration, data manipulation, and formatting.
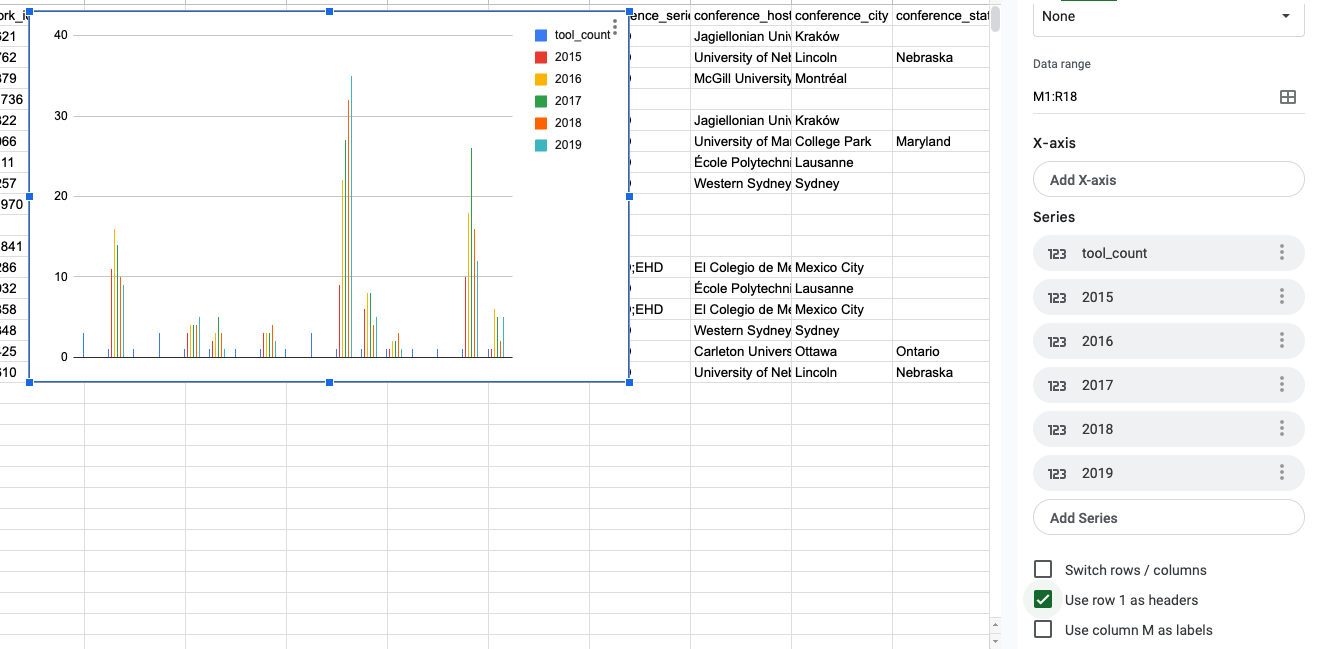
For instance, designating row 1 as headers offers a clearer representation: Google Sheets treats each column as an independent entity, manifesting as distinct bars on the chart.
Before we keep tweaking, it is often helpful to step back and think about what we are trying to visualize. In this case, we are trying to visualize the popularity of tools across our class and the Index of DH Abstracts. We can see that we have a column for tool_count and then a column for each year.
This raises some potential opportunities but also challenges. For example, if we want to compare this popularity across time, then we need to change our tool_count column to represent a year like 2023. However, we also have duplicates in that column because it is sharing the same value for each row.
So let’s create a new Sheet called Tools Popularity and copy our Final Merged Dataset into it. Next I’m going to delete a few of the columns that are less useful for this exercise. Depending on how your data is formatted, you might need to update any formula errors as well.
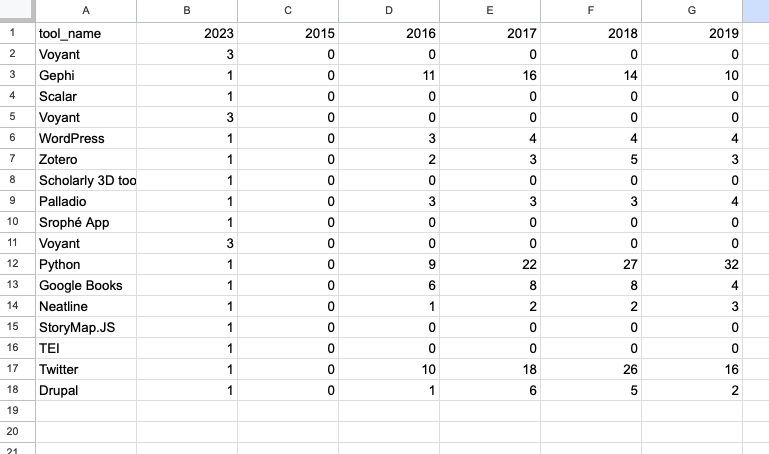
Your dataset should now resemble a truncated version of the original, with tool_count renamed to 2023. Creating a chart with this data yields:
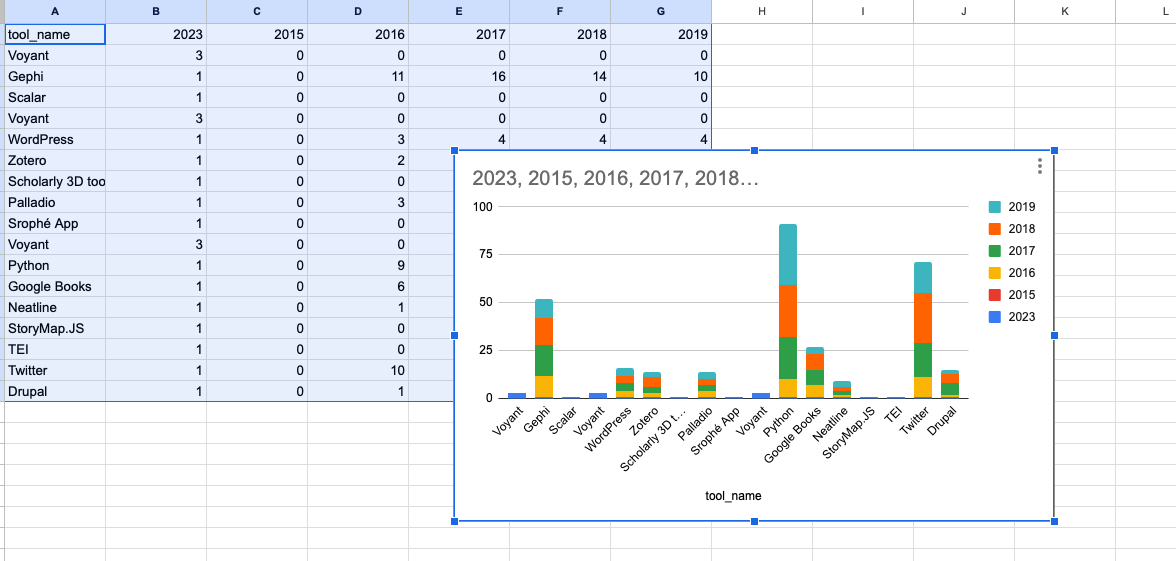
While this is an improvement, data duplication still remains a concern. With assistance from ChatGPT, we discern that Google Sheets offers a UNIQUE function, which, when employed, yields a duplicate-free version of our dataset.
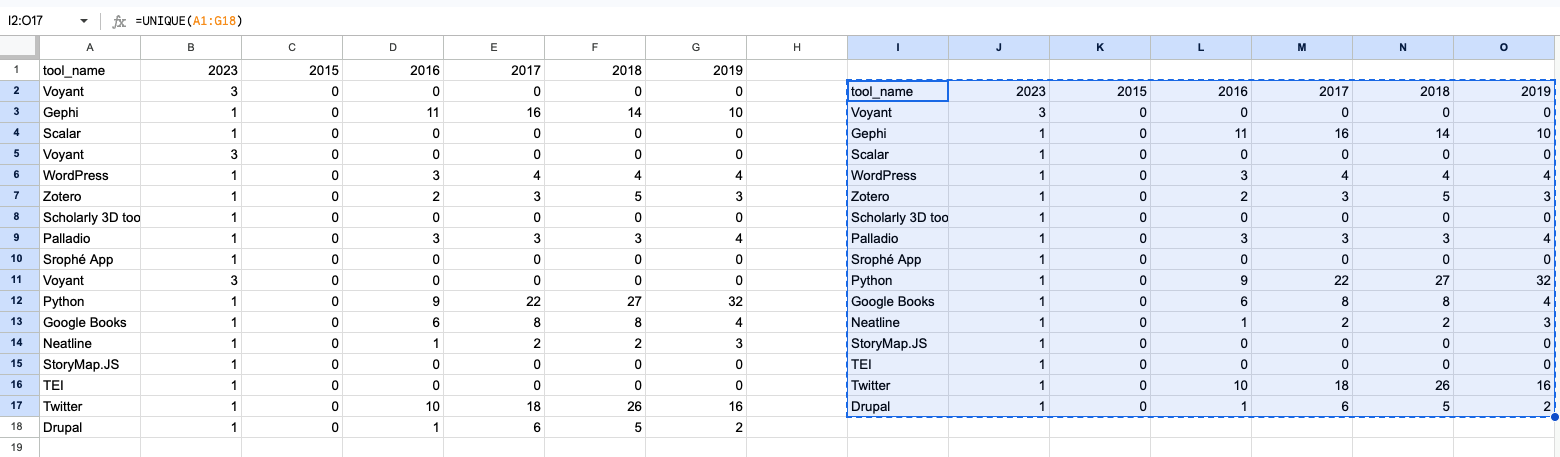
With this refined dataset, our chart becomes markedly more intelligible.
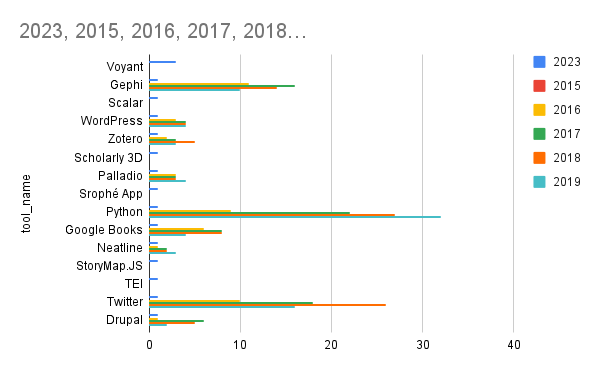
By stacking the chart, the popularity of the tools across datasets becomes more distinguishable. Particularly, Voyant emerges as a favorite in our class.
Data Visualization in DH
So far we have been particularly focused on how we can visualize our data in Google Sheets, but there are many other tools that we can use to visualize our data. In fact, there are many DH projects that are focused on data visualization. Here are a few examples:


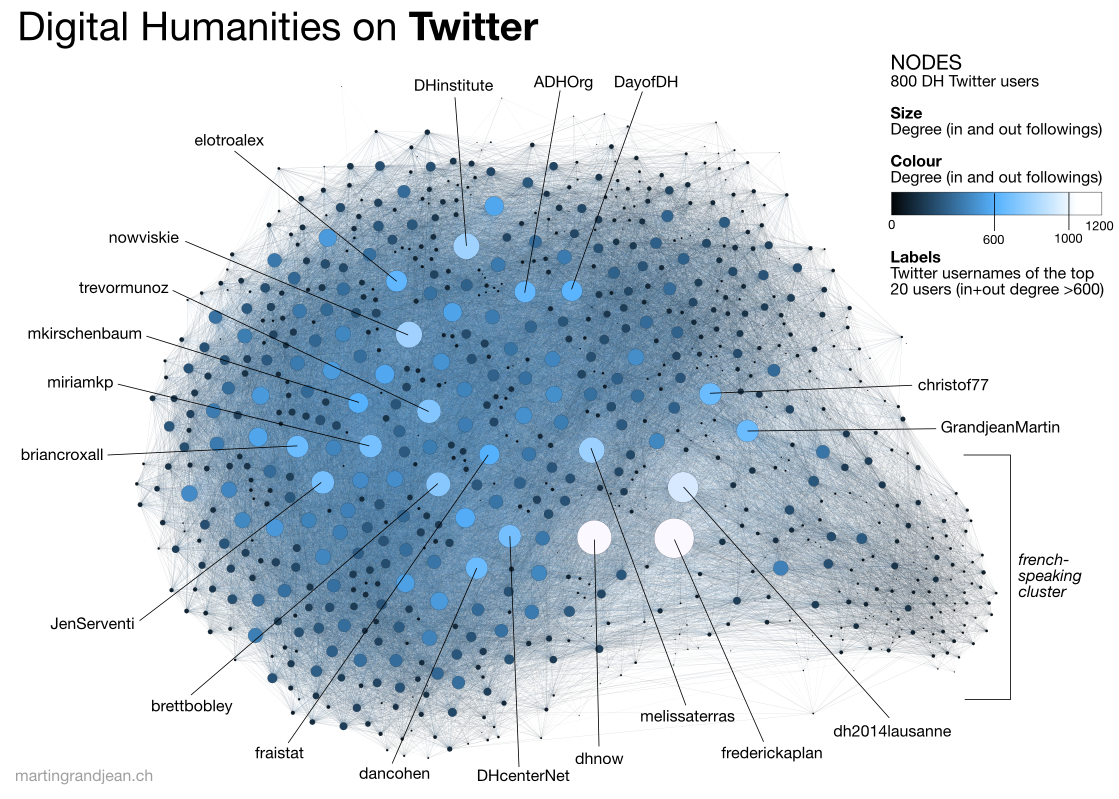
All of these projects use data visualization in different ways, which brings us to the larger questions of why create visualization in the first place? There’s no definitive answer but I think these infographics provide some helpful overview/answers:
- From Jeffrey Heer:

- From Lisa Charlotte Muth:
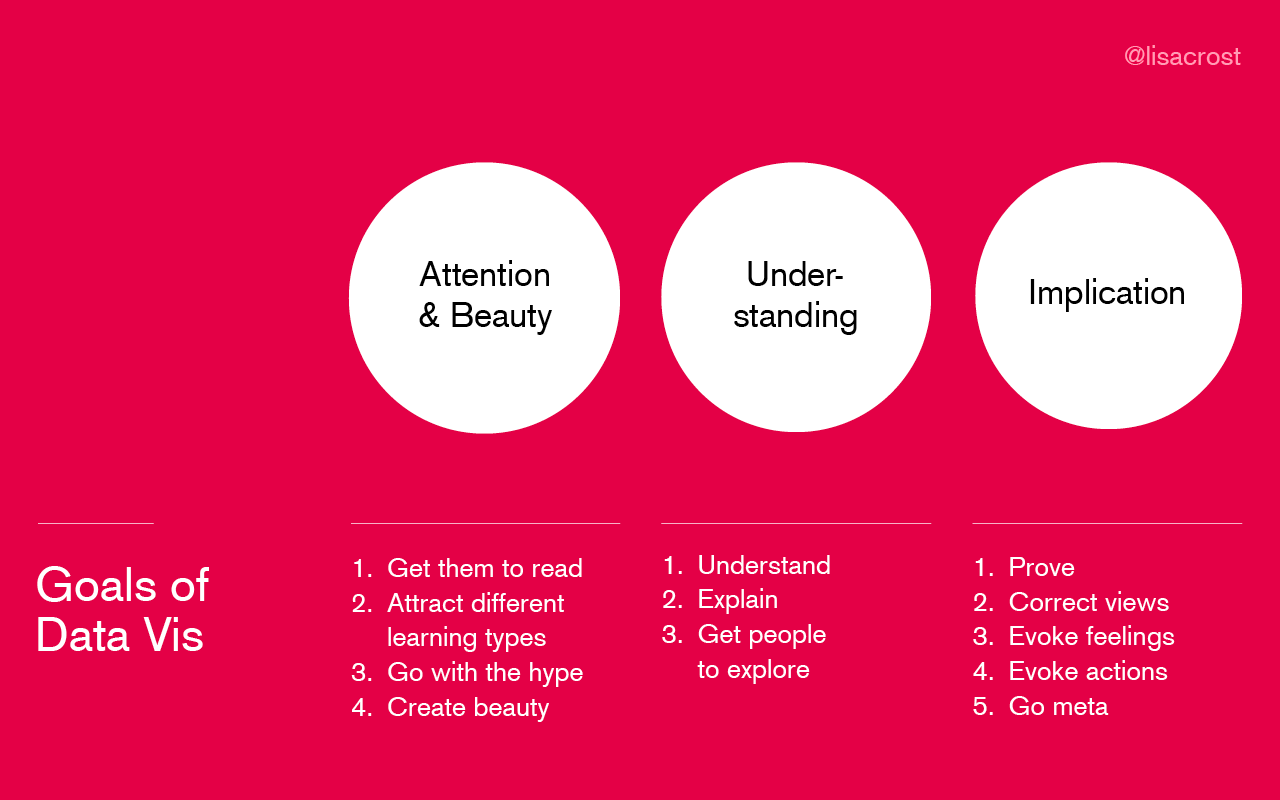
- From Duncan Geere:
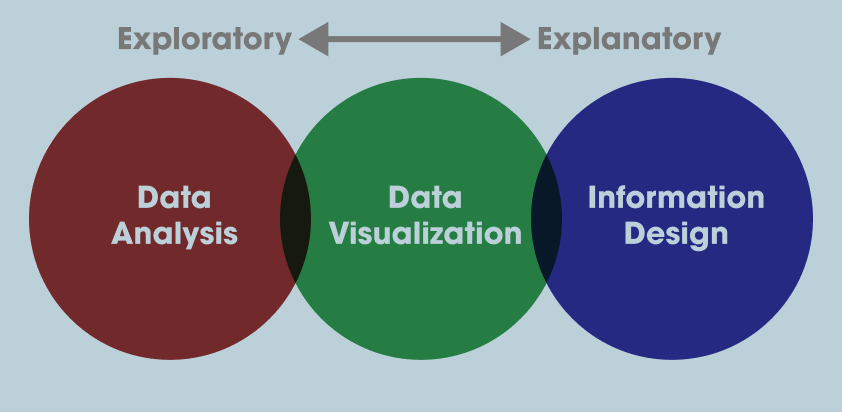
In-Class Assignment
Now that we have some foundation between our readings and these examples, we can start to dig more into what would be an interesting question to explore across these datasets (or within individual ones).
Working together in breakout rooms, spend ~10 minutes discussing what would be a potentially useful or impactful graph from this dataset, and also what might be some potential dangers in visualizing this data. You can use the following questions to help guide your discussion:
- What might be some interesting questions to explore with this data, especially based on our readings so far?
- What makes a good data visualization? Specifically in DH but also more broadly?
- What are the potential audiences for this data visualization? How would that impact the final output?
- What are some of the potential pitfalls of showing this data in aggregate? How does this distort its origins and how can we try to mitigate that?
I would also encourage you to draw on our applied readings from this week to help guide your discussion. For example, knowing some of the diversity issues in DH conferences, how might that impact our visualization of this data? Or knowing that data visualization is often used to make arguments, how might that impact our visualization of this data?
Advanced Data Visualization and Transposing Data
While Google Sheets is a great tool for visualizing data, it is limited in the types of visualizations it can create and is only one of many tools that can help us visualize data. One of my favorite tools for visualizing data is RawGraphs, a free and open-source tool tailored for crafting visualizations.
RawGraphs
We can easily try out RawGraphs by copying our data from Google Sheets and pasting it into RawGraphs.
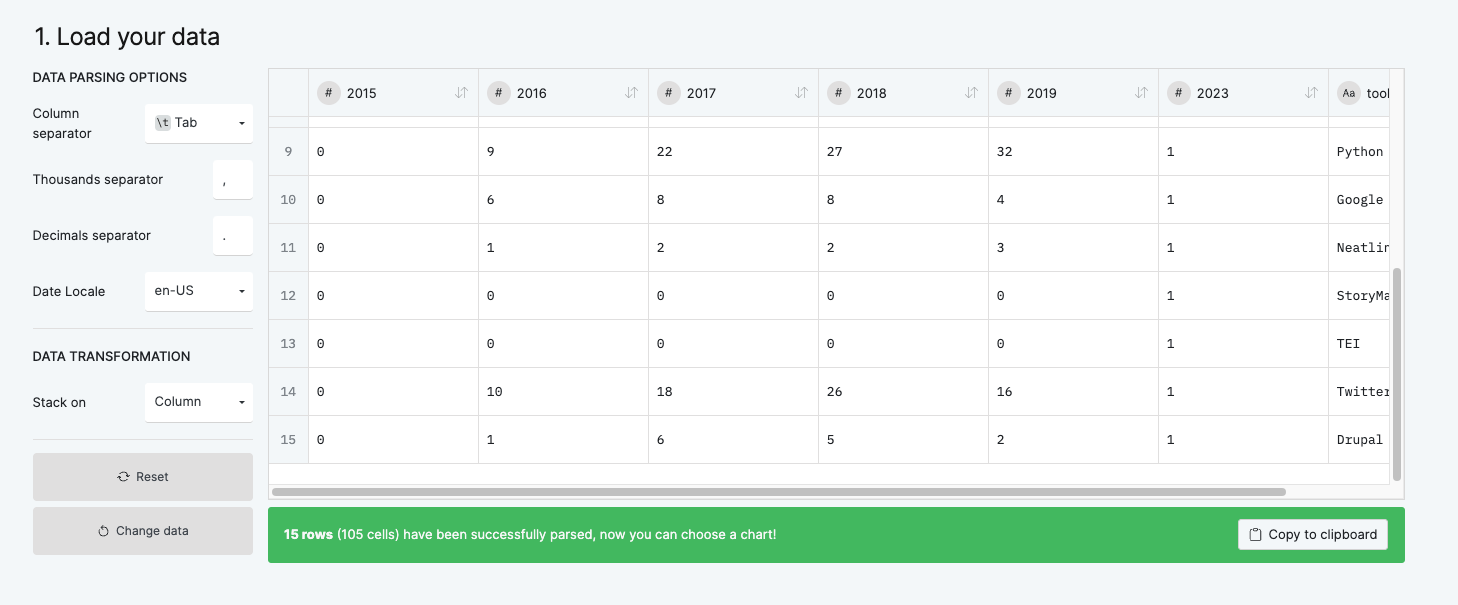
RawGraphs suggests we try something called an Alluvial Diagram, which is a type of flow diagram that can help us visualize how our data is changing over time.
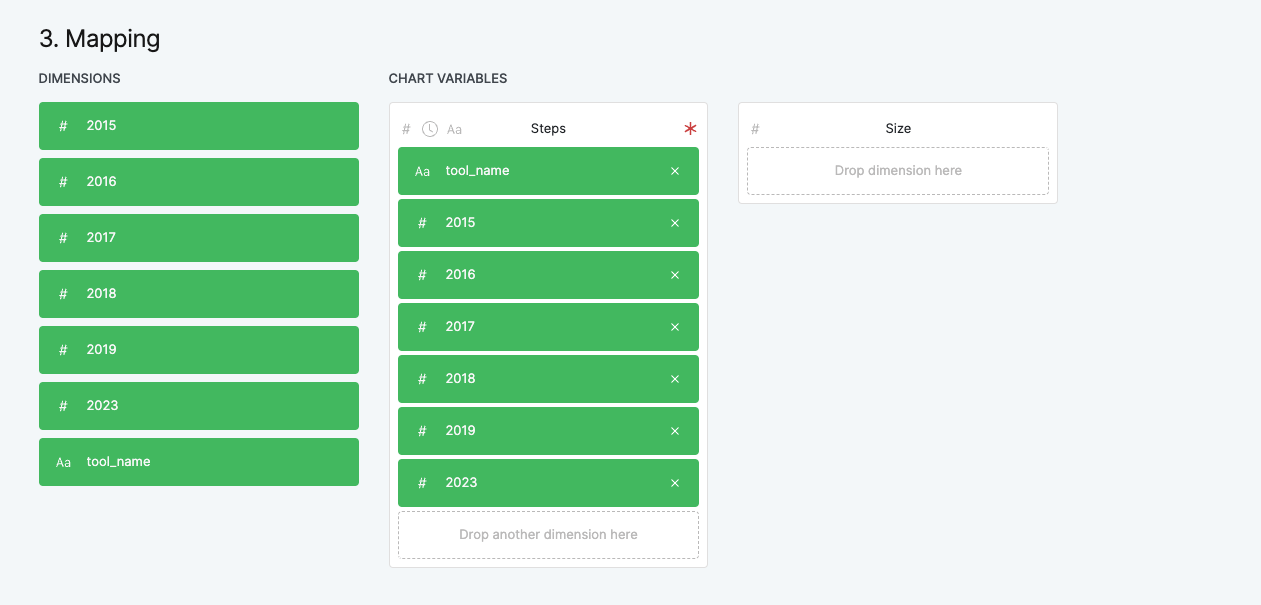
Once we enter the columns, we should see the following chart:
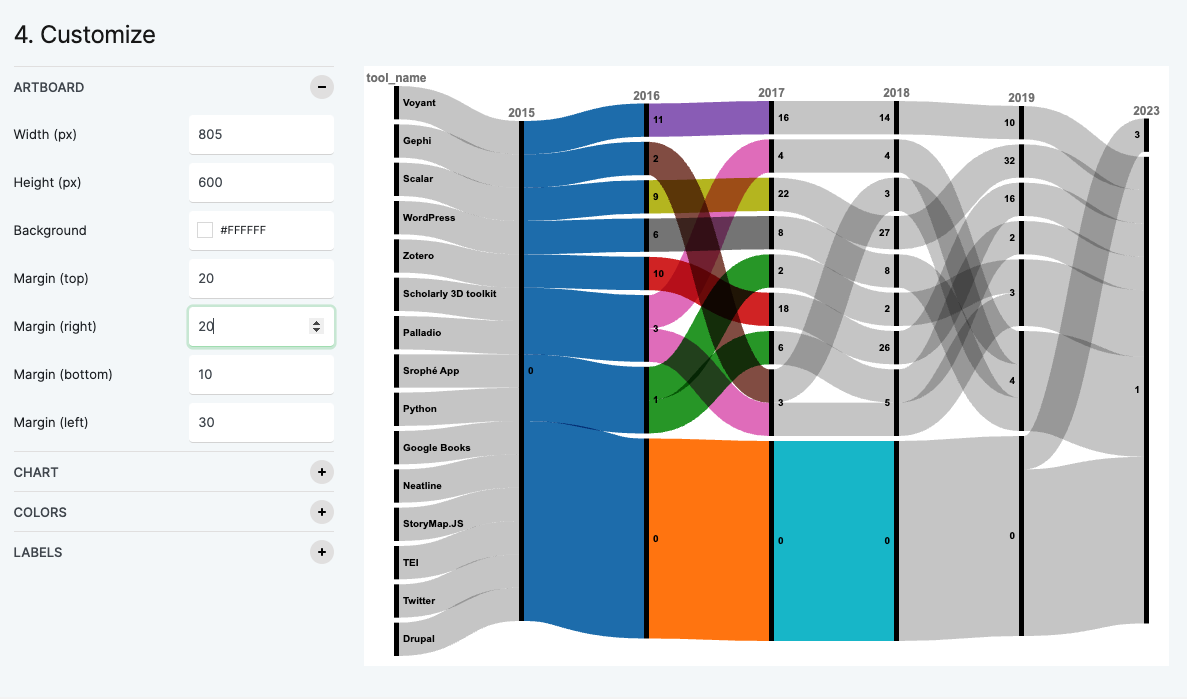
While this visualization offers an aesthetic upgrade from Google Sheets, it remains somewhat cluttered for temporal depictions. But you’ll notice that if we try to change our chart to one advertised as suitable for temporal data, like Bar or Line charts, RawGraphs prompts for X and Y axes.
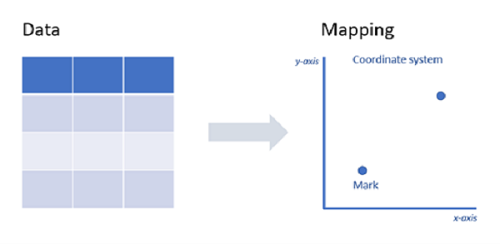
In data visualization, we often talk about the X and Y axes—horizontal and vertical axes of a chart. For example, in our data we might try to show year on the X axis since it is a continuous variable (i.e. time) and then the counts for each tool on the Y axis since it is a discrete variable. To do this though requires doing something called transposing our data.
Transposing Data
Transposing, while sounding sophisticated, simply involves switching rows and columns in datasets, as illustrated below. For our purpose, we aim to convert our year-based columns into rows.
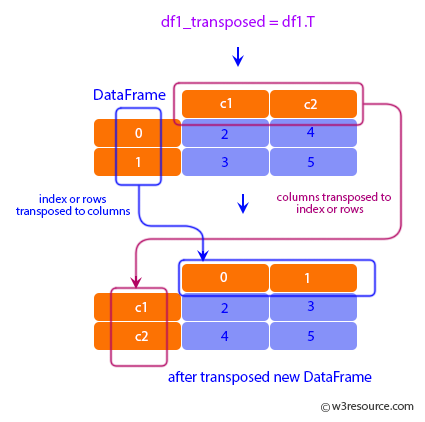
While we can do this in Google Sheets, OpenRefine’s interface is slightly easier to use for this type of transformation. So, to begin we can simply copy our data from Google Sheets and paste it into OpenRefine.
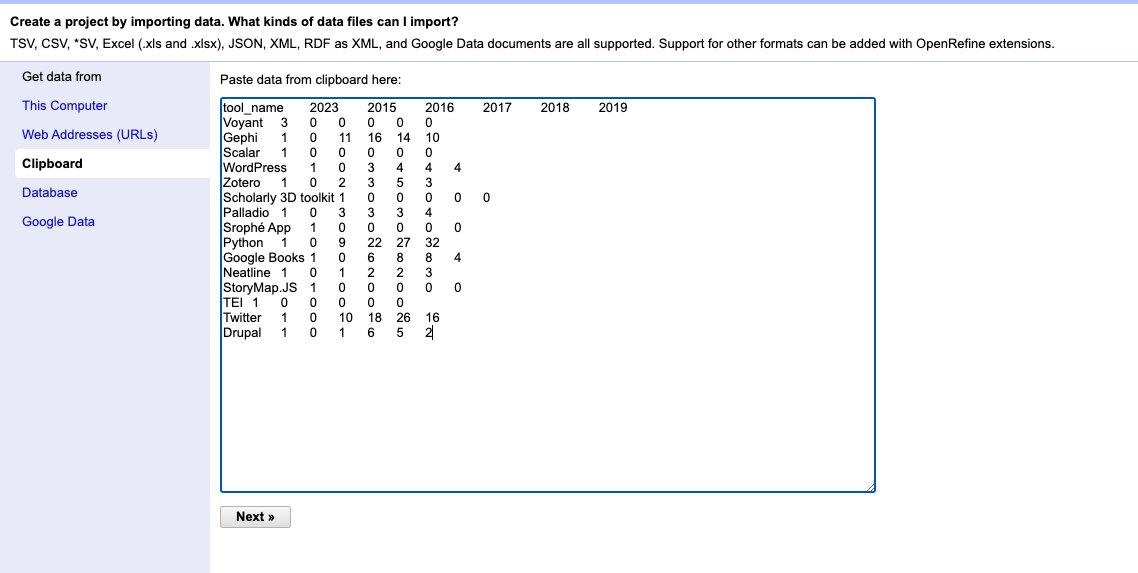
Select Clipboard and then Next.
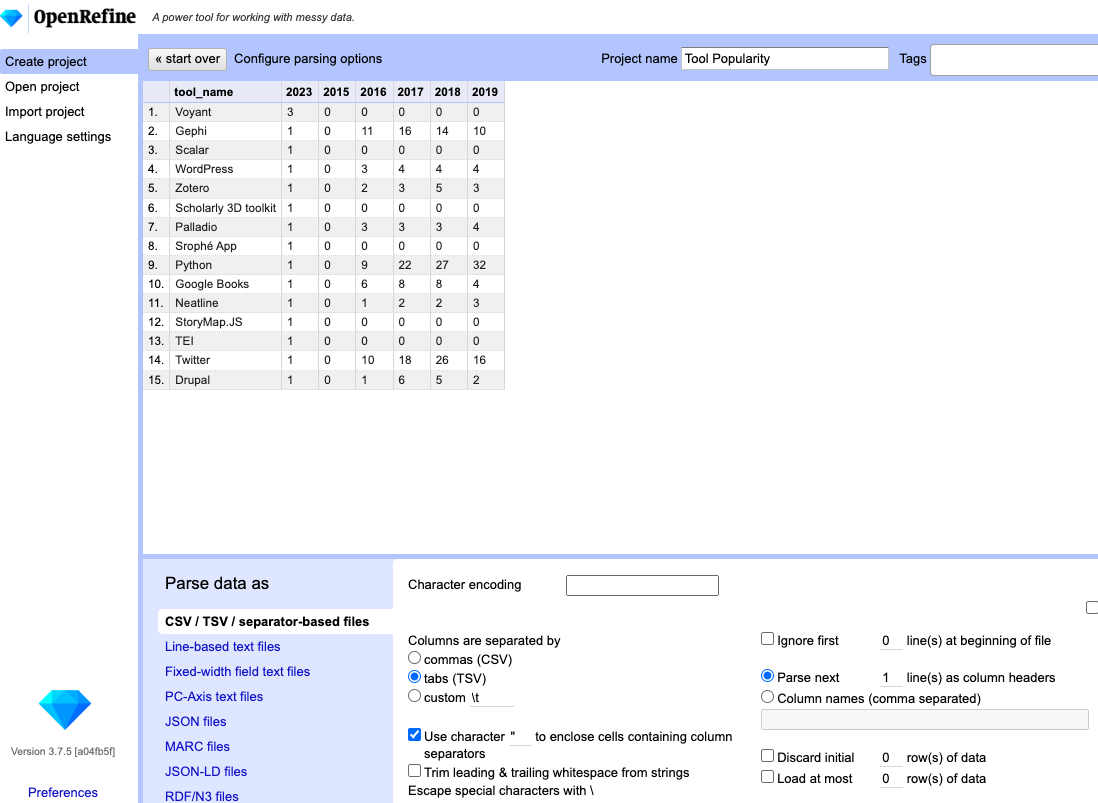
Then once you see the data preview, ensure Tab is chosen as the separator before initiating Create Project.
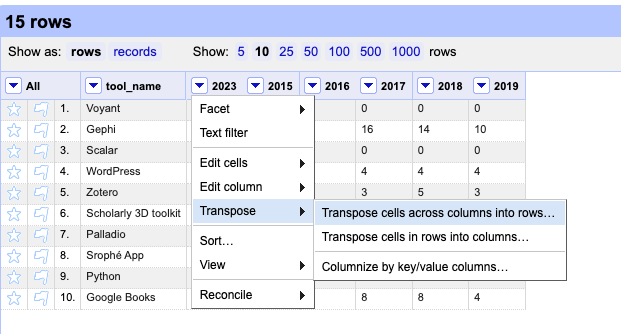
Now we can start transposing the data, by selecting the first column we want to transpose. One gotcha is that OpenRefine will transform all subsequent columns, so we need to be careful to only select the first column we want to transpose and that our column ordering conforms to this choice. For more information about transposing, I would highly recommend checking out the documentation https://openrefine.org/docs/manual/transposing
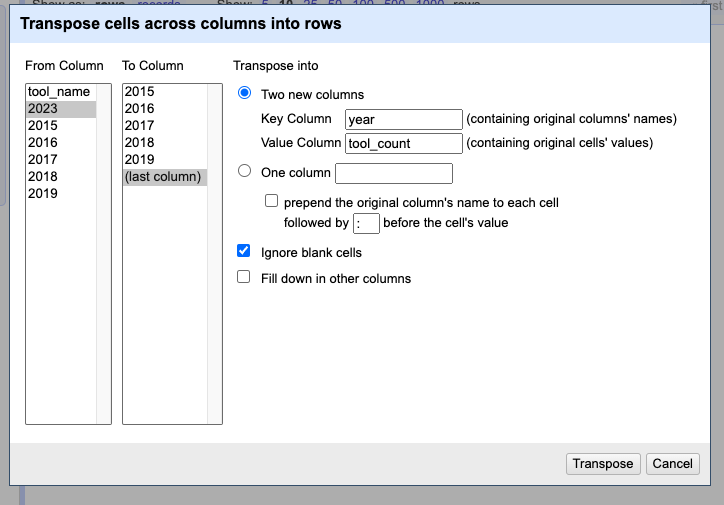
Once we have selected the first column, we can select Transpose and then Transpose cells across columns into rows. This will raise the option of naming our new columns. Again remember we are changing our data from columns to rows, so we want to name our new columns something that makes sense. In our case, we want to name our new columns year and tool_count.
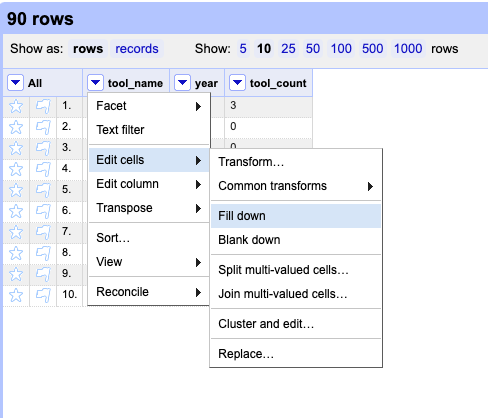
Now, we should have our dataset with three columns: tool_name, year, tool_count. The final step we need to do is to fill down the tool_name column, so that each row has a value for tool_name. We can do this by selecting the tool_name column and then selecting Edit Cells and then Fill Down.
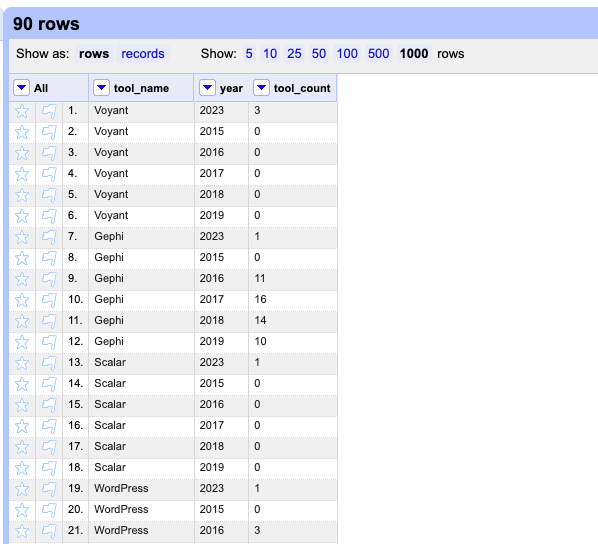
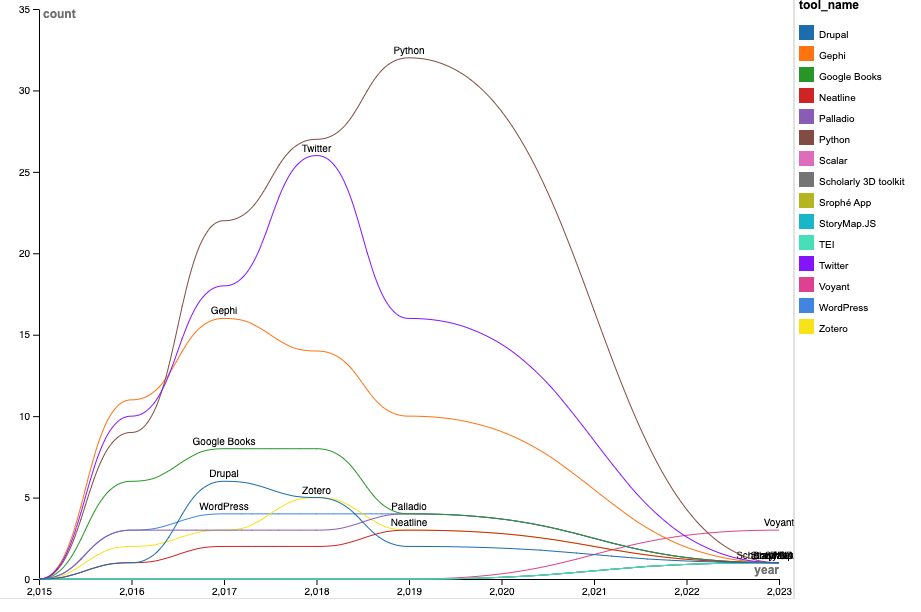
The result is a dataset that is transposed, which we can now copy and paste, or download and upload into RawGraphs to try creating a graph that shows change over time.
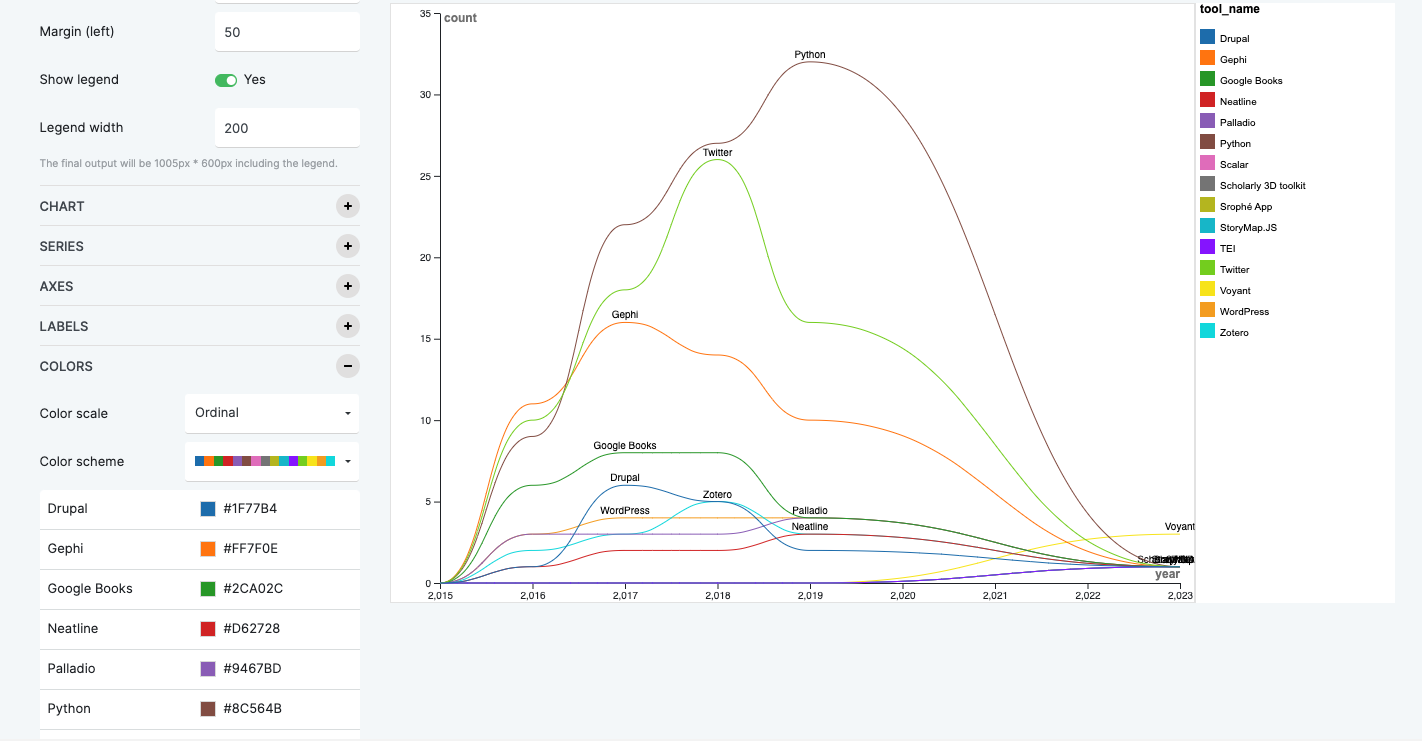
Here’s my first attempt using RawGraphs’ Line Chart feature, augmented with a color gradient for distinct tool differentiation.
Data Visualization Assignment(s)
We are trying something slightly different this week to accomodate everyone’s differing interests and pace. You have the option of completing any (or all) of the following assignments. What you select should be geared towards your interests. For example, if you plan to work with data than I would recommend assignment 2 , but if you plan to primarily assist others in finding materials than assignment 1 might be more appropriate. As always in this course there is no wrong answer or choice, but I would recommend trying to challenge yourself (though again what that means is for you to decide). Both assignments should be shared in this GitHub Discussion Forum https://github.com/ZoeLeBlanc/is578-intro-dh/discussions/5 and please specify which assignment you are sharing with your submission.
- Trends: Finding and Inspecting DH Data Visualization Examples
For this assignment, the goal is to find examples of data visualization in DH and trying to identify how the visualization (broadly defined) was created. You can use the examples above or from the readings or find your own. The goal is to try to find at least 2 examples, and then try to identify the following:
- How was the visualization created? What tools were used?
- What does this visualization tell us about not only the data, but trends in DH more broadly?
You are welcome to either create a Markdown file and link to that in the relevant GitHub discussion, or simply post your findings directly in the discussion. If you are having trouble finding examples, please let me know and I can help you with your search.
- Outliers: Testing and Creating New Data Visualizations
For this assignment, the goal is to try making data visualizations using data from this course with tool you have never used before. You can use the tools we discussed in class but would also recommend potentially trying something like DataWrapper https://www.datawrapper.de/ or Flourish https://flourish.studio/. The goal is to try to create at least one graph and explain your rationale. You should share your graph and rationale in the relevant GitHub discussion, which you can do directly in the forum or link a Markdown file from a repository.
You are welcome to use your own version of our merged DH tools dataset, or you can use the version from class (available here), or my preferred option would be that you try using a dataset I compiled that contains not only counts from the blog post or class, but also all mentions of individual tools in the Index of DH Conferences. You can access the data in our course repository with this link https://github.com/ZoeLeBlanc/is578-intro-dh/blob/gh-pages/public_course_data/all_tool_counts.csv. You’ll notice that if using this dataset some of the columns match our existing ones, but you’ll need to do some investigating to understand the remaining ones.
Tutorials for using new tools (again, tool choice is yours):